The Benchmark Crisis
We’ve known for a while that AI benchmarks saturate fast. GPQA — graduate-level questions designed to be “Google-proof” — went from impenetrable to near-solved in under a year. But what’s happening now is qualitatively different: we’re not just running out of easy benchmarks, we’re running out of hard ones. The very tools we use to upper-bound AI capabilities are collapsing, and the consequences for safety governance are severe.
The METR Time Horizon Problem
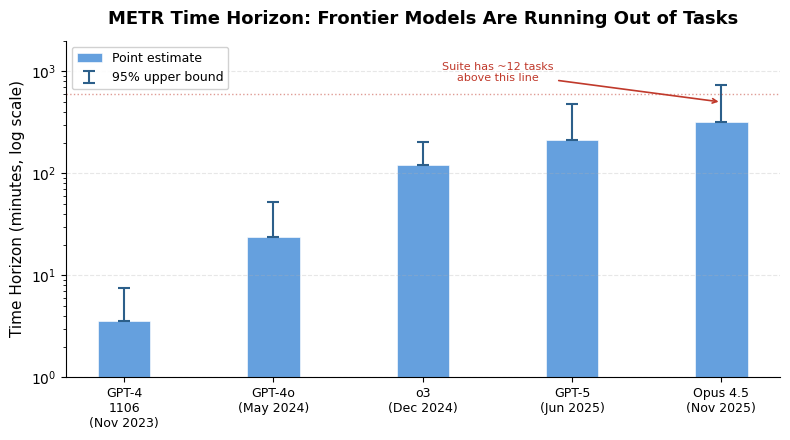
METR’s Time Horizon suite was the gold standard for measuring autonomous AI capability. The idea is elegant: calibrate tasks against human completion times, then measure what length of task an AI can reliably complete. As of TH1.1 (released January 2026), the suite contains 228 tasks, up from 170. But frontier models — Claude Opus 4.6, GPT-5.3 — can now complete all but roughly a dozen of them. Claude Opus 4.5 has a 50% time horizon of about 5 hours under TH1.1, but with a 95% upper confidence bound stretching to 60 hours. That’s a 12x uncertainty range. When your error bars are wider than your measurement, the measurement has stopped being useful.
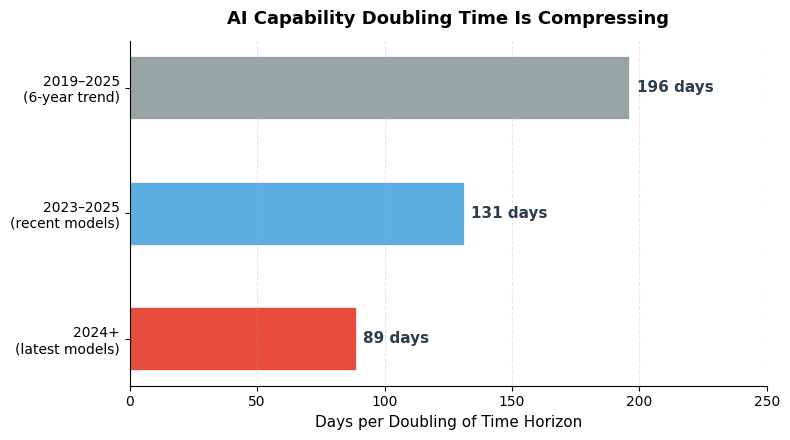
The trend is accelerating uncomfortably. METR’s own data shows the doubling time for time horizon has compressed from ~196 days (2019–2025) to 88.6 days for models released since 2024. At that rate, if a model today can handle 5-hour tasks, within six months it’s handling 10-hour tasks, and within a year, 20-hour tasks. The TH1.1 suite simply doesn’t have enough long tasks to track this curve. Creating more is brutally expensive: METR estimates that producing 50 new 32-hour tasks with two human baselines each would require over 3,200 hours of specialist time, costing north of $1 million. And by the time those tasks are validated and released, there’s a real chance they’ll already be within reach of the next generation of models.
The Contamination Ratchet
There’s a structural problem that makes this worse than simple cost: data contamination. Once a benchmark problem appears in any public form — paper, leaderboard, discussion forum — it enters the training corpus for future models. This means benchmarks have a finite shelf life. They degrade with each model generation. The “open problems” approach (FrontierMath, unsolved conjectures) sidesteps contamination by using problems that literally no one has solved, but these are one-shot: once a model cracks a FrontierMath problem, that problem is spent. You can’t re-use it. This creates an arms race where benchmark creation must permanently outpace model improvement, and the economics are working against us.
Anthropic’s own safety framework illustrates the stakes. When evaluating whether Opus 4.6 warranted an ASL-4 classification (the ability to autonomously perform entry-level research work), the company reportedly exhausted its formal eval suite and fell back on subjective surveys of 16 internal researchers. That’s not a measurement — it’s an opinion poll. When the most safety-conscious AI lab on Earth is resorting to vibes-based capability assessment, the measurement crisis is no longer theoretical.
What Comes After Benchmarks?
The field is groping toward alternatives, each with serious tradeoffs. Uplift studies (measuring real-world productivity gains) are high-fidelity but take months to execute. Third-party audits with privileged model access would be ideal but barely exist. Expert forecasting is fast but biased. The most intellectually honest approach — open problem benchmarks — acknowledges that AI has essentially solved the domain of “things humans can reliably and measurably do.” We’re now testing whether AI can do things no human has ever done, which is a fundamentally different question with fundamentally different governance implications.
My take: this is genuinely alarming, not because AI is necessarily dangerous right now, but because our ability to know whether it’s dangerous is eroding faster than our ability to make it more capable. The entire safety framework for frontier AI — Anthropic’s RSP, OpenAI’s Preparedness Framework, the EU AI Act’s risk tiers — rests on the assumption that we can measure capabilities before they manifest in deployment. If that assumption fails, we’re flying blind. The 88-day doubling time for time horizons means we’re approaching a world where, by mid-2027, no existing benchmark can rule out dangerous capabilities from frontier systems. That’s not a distant future problem. That’s 14 months from now.
Sources
- We’re actually running out of benchmarks to upper bound AI capabilities — LessWrong
- Time Horizon 1.1 — METR
- Clarifying limitations of time horizon — METR
- A benchmark of expert-level academic questions to assess AI (HLE) — Nature
- Humanity’s Last Exam — Epoch AI