Anthropic's Advisor Tool and the Rise of "Inverted Agents"
The End of the All-or-Nothing Model Choice
Anthropic shipped something quietly significant this week: the Advisor Tool, a beta API feature that lets a cheap executor model (Sonnet or Haiku) consult a powerful advisor (Opus) mid-task without the developer orchestrating the handoff. On paper, it’s a one-line API change — add a tool with type: "advisor_20260301" and a model: "claude-opus-4-6". But it represents a real architectural shift in how we think about inference economics, and it deserves more attention than the usual “new feature dropped” coverage.
The traditional approach to model routing has been a two-model pipeline where you either (a) run everything through the expensive model, or (b) build a separate classifier to decide which model handles each request. FrugalGPT and RouteLLM both explored this space — train a small router, cascade from cheap to expensive, optimize the cost-quality Pareto frontier. The problem was always complexity: you needed a separate routing layer, prompt adaptation logic, and careful threshold tuning. Anthropic’s advisor tool takes a different approach entirely. Instead of routing requests between models externally, it lets the executor model decide for itself when it needs help. The cheap model drives the entire task and calls the advisor only when it hits a decision too complex to resolve alone.
The Numbers Tell a Compelling Story
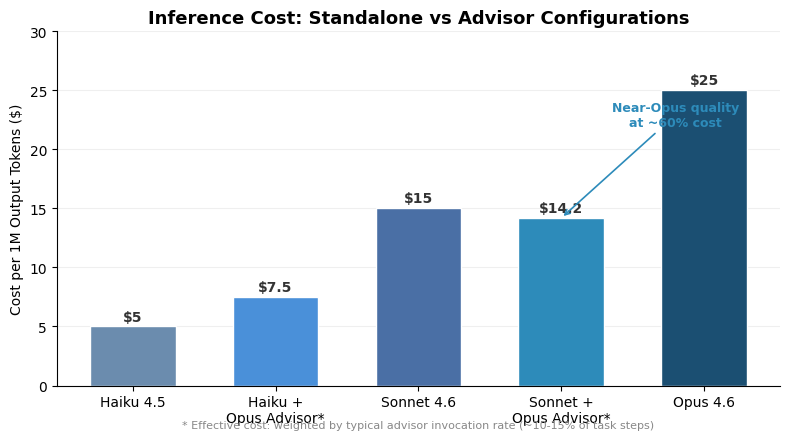
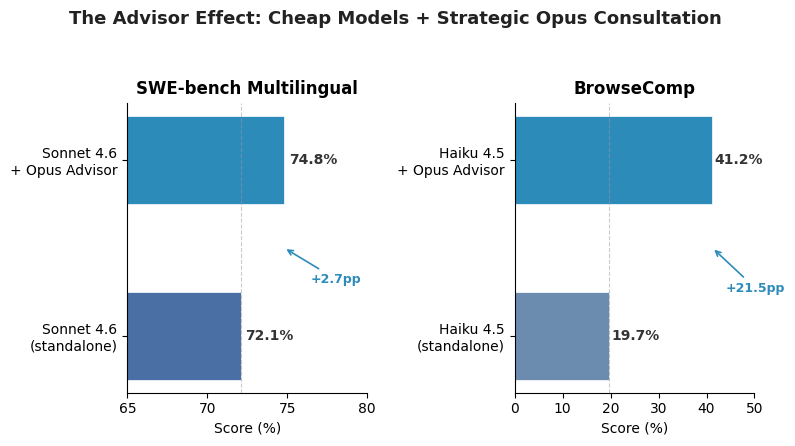
The benchmark results are striking, especially for the smallest models. Haiku 4.5 with an Opus advisor scored 41.2% on BrowseComp — up from 19.7% standalone, more than doubling its capability. On SWE-bench Multilingual, Sonnet 4.6 jumped from 72.1% to 74.8% with the advisor, a meaningful gain in a benchmark where every percentage point represents real GitHub issues from production codebases. Eve Legal, an early adopter, reported that Haiku + Opus advisor matched frontier-model quality at 5x lower cost than running Opus directly. The 11.9% cost reduction per agentic task for the Sonnet configuration sounds modest until you multiply it across thousands of agent runs.
What’s happening here is essentially a software-level mixture-of-experts. Traditional MoE architectures route between expert sub-networks within a single model at the hardware level. The advisor tool does the same thing at the API level, but with a critical difference: the routing decision is made by a model that understands the task context, not by a lightweight classifier looking at surface features. When Sonnet calls the advisor, it’s not because a router flagged the input as “hard” — it’s because Sonnet genuinely hit a wall and knows it. That’s a qualitatively better routing signal.
Why This Matters Beyond Anthropic
The implications extend well beyond one vendor’s API. This pattern — small model drives, big model advises — is likely to become the default architecture for production AI agents within 12 months. The cost math is too compelling to ignore. Opus output tokens cost $25 per million; Sonnet costs $15; Haiku costs $5. If 80% of an agent’s work is mechanical (tool calls, formatting, file operations) and only 20% requires frontier reasoning, you’re paying Opus rates for work that Haiku could do blindfolded. The advisor pattern captures that surplus.
But there’s a subtlety that the marketing glosses over: latency. Every advisor call adds a server-side round-trip, and the advisor’s output (1,400–1,800 tokens including internal thinking) takes time to generate. For interactive coding agents where you’re watching output stream in, that pause is noticeable. Anthropic’s documentation acknowledges this — priority tier status on the executor doesn’t automatically apply to the advisor. For batch workloads and background agents, this is a clear win. For interactive use, the tradeoff is murkier.
The Harder Question: When Does the Advisor Help?
Not all tasks benefit equally. The advisor tool shines when a task has a “lumpy” difficulty distribution — mostly easy steps punctuated by genuinely hard decisions. Coding agents are the canonical example: scaffolding files, running tests, and reading error logs are routine, but designing the right abstraction or debugging a race condition needs real reasoning. For uniformly complex tasks (deep mathematical proofs, novel research synthesis), you’re better off just running Opus. For uniformly simple tasks (data extraction, classification), the advisor overhead isn’t worth it.
The max_uses parameter is the key lever here. Anthropic recommends setting it conservatively — the caching break-even point is 3 advisor calls per conversation. Go beyond that and you’re paying Opus rates often enough that the cost advantage erodes. The 35–45% output token reduction from constraining advisor responses to under 100 words is another practical optimization that the docs mention but most developers will miss.
This is, in my assessment, one of the more genuinely useful API-level innovations in the LLM space this year. Not because the idea is novel — orchestration frameworks like LangGraph have supported similar patterns — but because Anthropic collapsed the complexity into a single tool definition. No frameworks, no routing logic, no context management. That’s the kind of developer experience that drives adoption.
Sources
- Anthropic Advisor Tool Documentation
- Anthropic Advisor Strategy Guide
- RouteLLM: Learning to Route LLMs with Preference Data
- FrugalGPT: How to Use LLMs While Reducing Costs
- SWE-bench Multilingual Leaderboard
- Claude API Pricing Guide 2026