Less Data, Smarter Models
The Hook
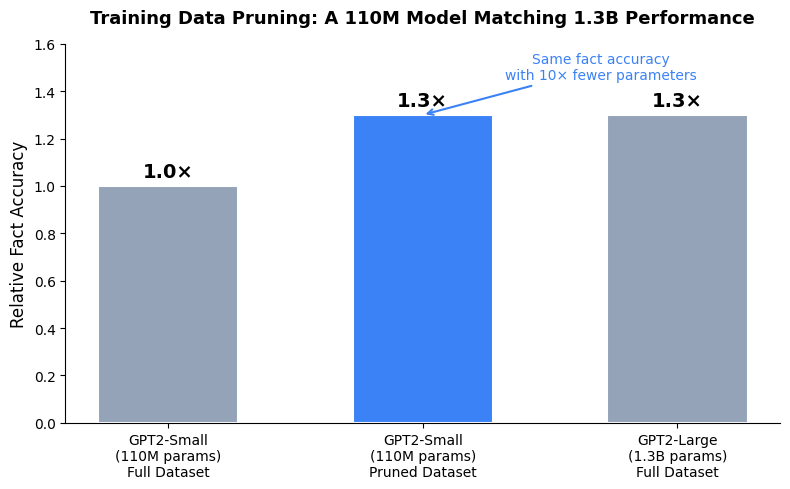
Apple Research, in collaboration with the National University of Singapore, just published work that sounds like it shouldn’t work: throwing away training data makes language models memorize more facts, not fewer. The paper, “Cram Less to Fit More,” accepted at ICLR 2026, formalizes fact memorization from an information-theoretic perspective and demonstrates that the standard approach to LLM training — feed the model everything you have — is provably suboptimal when it comes to factual knowledge retention. The headline result is striking: a GPT2-Small model (110M parameters) trained with Apple’s data pruning method memorized 1.3× more entity facts than the same model trained on the full unpruned dataset, and matched the fact accuracy of a 10× larger model (1.3B parameters) trained on all of that data.
The Analysis
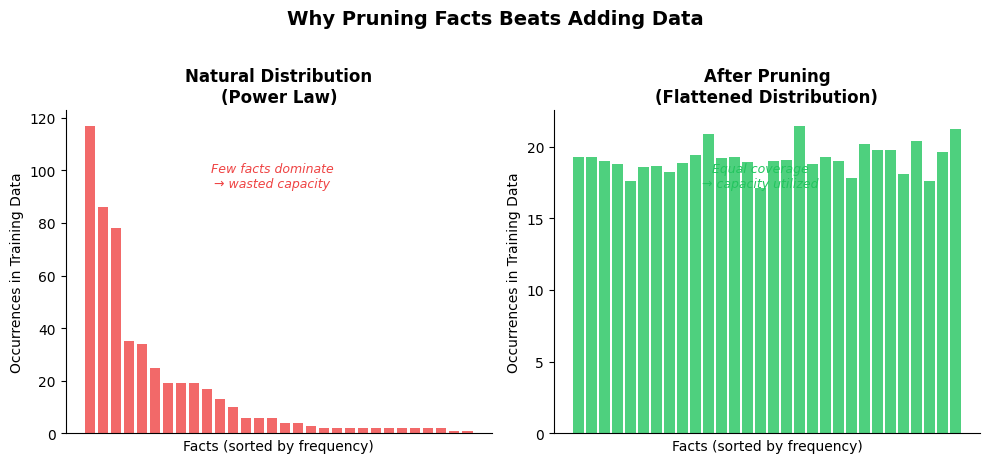
The core insight hinges on how factual knowledge distributes across real-world training corpora. Natural language follows a power law — a few facts appear extremely frequently (celebrity names, famous locations, canonical events) while the vast tail of factual knowledge appears rarely or only once. When a model trains on this skewed distribution, it over-learns the popular facts and under-learms the long tail. The researchers prove that whenever the total information content of facts in the training data exceeds the model’s memorization capacity, accuracy degrades below the theoretical limit — and power-law distributions make this worse, because they force the model to spend disproportionate capacity on redundant, high-frequency facts.
Their solution is elegantly simple: use training loss as a signal to identify which data points contain facts the model has already absorbed, and prune those. This flattens the effective frequency distribution, allowing the model’s fixed parameter budget to cover a wider range of factual knowledge. The method works at two levels — first on semi-synthetic datasets (synthetic phonebooks, title-author mappings in arXiv papers) where they can precisely measure fact accuracy against a known capacity limit, then on real Wikipedia corpus pretraining where the effect translates to the dramatic GPT2-Small result.
This has significant implications for how we think about the compute-data tradeoff. The Chinchilla scaling paradigm established that most models are undertrained relative to their parameter count, and the industry response was to throw more tokens at existing architectures. Apple’s result suggests that the composition of those tokens matters at least as much as their volume. A model that sees 80% of its training data but sees it with a flatter fact distribution may genuinely outperform one that sees 100%. For the growing ecosystem of local and edge-deployed models — Qwen, Gemma, Phi — where parameter budgets are tight, this is directly actionable research.
The Implications
The paper lands at an interesting moment. The “Top Local Models” survey from Latent Space this week shows Qwen 3.5, Gemma 4, and GLM-5 competing fiercely for local deployment mindshare. These are all models where training efficiency is a real competitive advantage. If fact memorization can be boosted 1.3× through smarter data curation rather than more parameters, it changes the calculus for every lab training models under 10B parameters. You don’t need a bigger model; you need a smarter training set.
There’s also a subtle implication for the hallucination problem. If a primary driver of hallucinations is the model failing to memorize low-frequency facts correctly, then flattening the fact distribution during training directly attacks a root cause. Apple doesn’t make this claim explicitly — their scope is memorization accuracy, not open-ended generation quality — but the connection is hard to ignore. A model that has genuinely memorized more of its training facts has a broader factual foundation to draw from during inference.
The Counterpoint
The elephant in the room is compute cost. Apple’s pruning method requires running training loss evaluations on candidate data subsets, which adds overhead during the data curation phase. For massive frontier models trained on trillions of tokens, the marginal cost of this curation might not justify the gains. But that’s precisely the point — this research isn’t aimed at frontier labs with unlimited budgets. It’s aimed at the broad middle: researchers, startups, and companies deploying models where every parameter counts. And on that front, the math is compelling. A 10× reduction in effective model size (110M matching 1.3B) for the same factual accuracy is a remarkable return on a data engineering investment.
My take: this is one of those papers that will be more cited in two years than it is today, because the industry is slowly shifting from “scale everything” to “optimize everything.” Apple’s been quietly strong on the data-efficiency front, and this result — despite being from a workshop paper rather than a main conference track — deserves to reshape how smaller labs approach pretraining.
Sources
- Cram Less to Fit More: Training Data Pruning Improves Memorization of Facts — Apple Research & NUS, ICLR 2026 Workshop
- Apple Machine Learning Research page
- Top Local Models — April 2026 — Latent Space
- Chinchilla Scaling Laws — Wikipedia