Memory Is the New Runtime
The Bolting Era Is Over
Something shifted this week. Anthropic shipped filesystem-based memory for Claude Managed Agents. Stash, an open-source project, dropped a single-binary persistent memory layer that works with any MCP-compatible agent. Meta published a paper showing that structured summaries of past coding rollouts — a form of procedural memory — can push Claude-4.5-Opus from 70.9% to 77.6% on SWE-Bench Verified. These aren’t three separate stories. They’re the same story: memory is graduating from a kludge you bolt onto an agent to a primitive the runtime provides.
For two years, the industry’s answer to “my agent forgets everything” has been some variant of stuffing documents into a vector database and retrieving them with cosine similarity. RAG. It works for lookup. It fails for everything else — temporal reasoning, belief updating, contradiction handling, long-horizon learning. As one HN commenter put it while describing their own persistent agent: “The recurring question is whether the memory actually changes behavior, or whether it’s decoration.” That question has haunted every RAG pipeline that couldn’t tell you what its agent unlearned last Tuesday.
The paradigm is splitting, and the choice is architectural, not a feature checkbox. Five approaches have emerged, each modelling a fundamentally different kind of remembering.
Five Paradigms, Five Mental Models
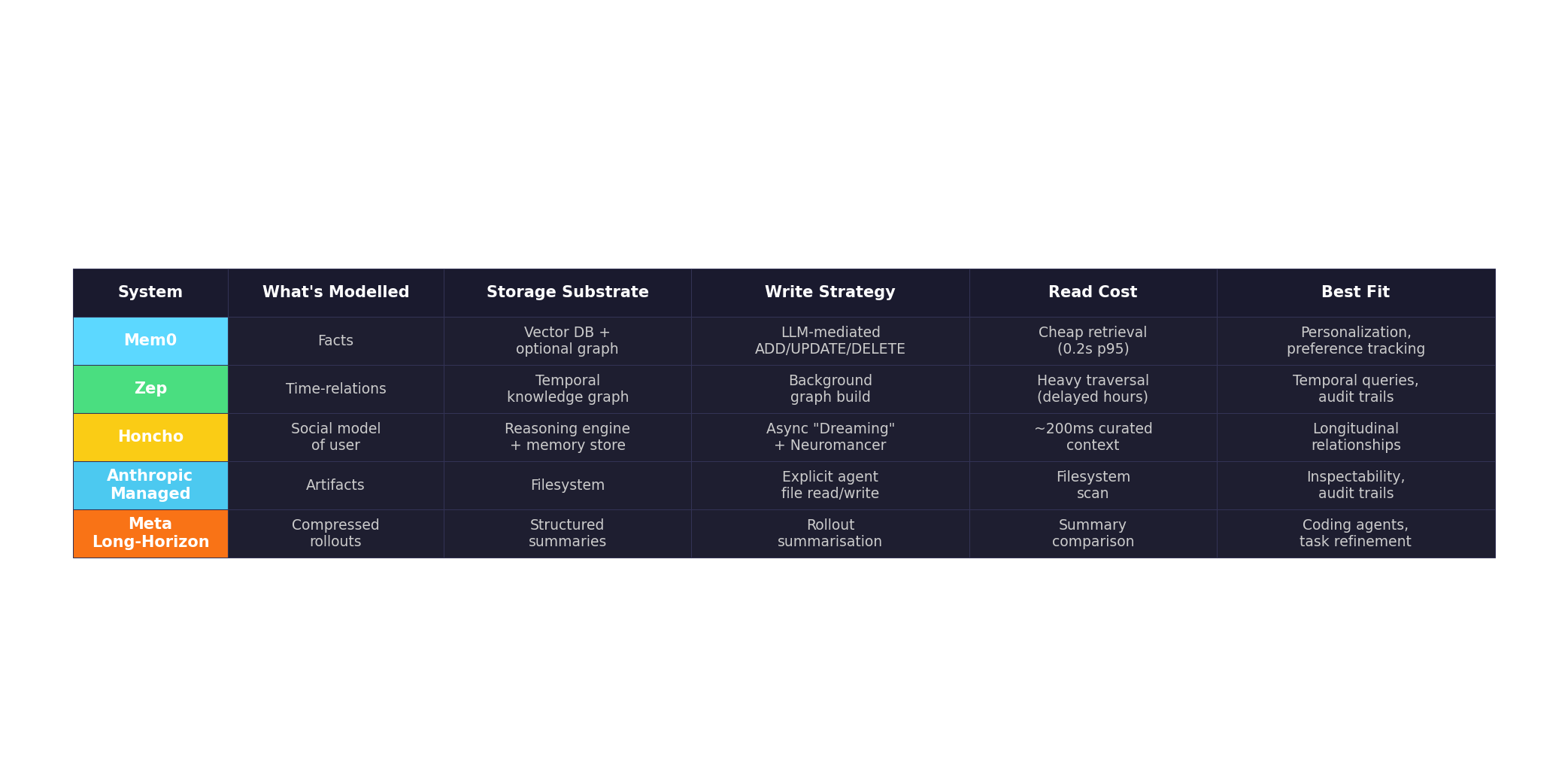
Mem0 treats memory as semantic extraction. An LLM evaluates each conversational turn and performs one of four operations — ADD, UPDATE, DELETE, or NOOP — against a fact database. This is CRUD for cognition. It drops token usage by roughly 90% compared to full-context approaches, and at 48,000 GitHub stars it has the largest community. But it’s lossy by design: you keep the conclusions, not the trail. There’s no native temporal model — a fact exists or it doesn’t, with no notion of “this was true in March but not April.” On the LongMemEval benchmark, it scores 49.0%. Its graph variant (Mem0g) does better on temporal reasoning (58.13% vs OpenAI’s 21.71%), but graph features are gated behind the $249/month Pro tier.
Zep builds temporal knowledge graphs via its Graphiti engine. Every edge carries explicit validity windows — valid_from, valid_to, invalid_at — making time a first-class dimension of every relationship. This lets it answer questions like “What was the customer’s address before they moved?” or “When did the team switch from Slack to Teams?” It scores 63.8% on LongMemEval, significantly ahead of Mem0. The tradeoff is brutal: memory footprint exceeds 600,000 tokens per conversation, and graph processing is so heavy that correct answers may not appear until hours after ingestion. The Community Edition is deprecated; self-hosting means managing your own Neo4j instance.
Honcho takes a different angle entirely: social cognition. Rather than modelling facts or temporal relations, it models the user — their evolving goals, dispositions, and patterns. Its Neuromancer reasoning engine runs asynchronously (“Dreaming”), testing hypotheses and resolving contradictions in the background without blocking the agent. It scores 89.9% on LoCoMo and 90.4% on LongMemS, with 60–90% token savings. The key insight: memory doesn’t just need to store, it needs to reason. At $2 per million tokens ingested with unlimited retrieval calls, it’s positioned for the kind of longitudinal relationship modelling that chatbots and interview agents require.
Anthropic’s Managed Agent Memory is the dark horse because it rejects the retrieval paradigm entirely. Memory is filesystem-based — artifacts the agent reads and writes, with full audit trails and rollback capability. This is memory as documents, not vectors. It’s human-inspectable, diffable, version-controllable. Netflix, Rakuten, and Wisedocs are already using it. The philosophical difference is profound: instead of asking “what does the agent remember?”, you ask “what did the agent write down?” That shift makes memory legible to humans in a way no embedding-based system achieves.
Meta’s long-horizon paper is the procedural cousin. The core idea: convert each agent rollout into a compact structured summary, then use those summaries for selection and reuse in future attempts. Their Recursive Tournament Voting and Parallel-Distill-Refine methods push terminal-Bench v2.0 scores from 46.9% to 59.1%. This isn’t memory in the conversational sense — it’s compressed experience, the way a chess player remembers patterns from thousands of games without recalling a single move sequence.
The Architectural Argument
What connects these five approaches is the thesis Mat articulated: memory is moving from application layer to runtime primitive. You don’t write your own garbage collector. You shouldn’t have to write your own memory consolidation pipeline either. The question is what shape that primitive takes.
Cloudflare sees it too — they launched Agent Memory as a managed service two weeks ago, explicitly targeting “agents running for weeks or months against real codebases.” The Register’s coverage of agentic memory hierarchies notes the infrastructure implication: KV cache is becoming the bottleneck, not compute. Nvidia’s Inference Context Memory Storage and CXL interconnects are hardware responses to the same problem the software world is trying to solve at a higher abstraction layer.
This is where the benchmark wars get revealing. The field can’t even agree on what to measure. LOCOMO tests 10 extended conversations. LongMemEval pushes to 1.5 million tokens across 500 questions. BEAM tests knowledge updates, contradiction handling, and abstention at 100K to 10M tokens. Vendors cherry-pick their best metric: Mem0 leads on LOCOMO, Honcho on BEAM, Zep on structural reasoning. The disarray isn’t sloppiness — it reflects genuine disagreement about what memory is for.
Which Memory for Which Agent?
The choice depends on what kind of relationship matters for the task. For a longitudinal interview chatbot running across weeks of qualitative data collection, you need temporal reasoning (when did the participant say this?) and belief updating (they contradicted themselves — which version is current?). Zep’s temporal graph or Honcho’s reasoning engine are the natural fits. For a coding agent that runs the same repo daily and needs to get better at it over time, Meta’s procedural summaries or Anthropic’s filesystem artifacts make more sense — memory as accumulated craft, not accumulated facts. For a customer support agent that needs to remember preferences and past issues, Mem0’s fact-store is efficient and sufficient.
For the kind of work we actually care about — qualitative data processing across multiple sessions, repeated agentic tasks against a shared corpus — the honest answer is that no single paradigm covers it. You need Honcho-style reasoning about the user’s evolving position, filesystem artifacts for inspectable intermediate results, and procedural memory for task refinement. The monolithic memory system is a trap. The future is composable: different substrates for different kinds of remembering, orchestrated by the agent itself.
The RAG hype train, which long since proved pretty limited, is being replaced by something harder and more interesting. Memory is no longer about retrieval. It’s about what an agent chooses to learn, how it decides what’s worth keeping, and whether the resulting knowledge is legible to the humans who built it. The shape of memory you pick shapes the kind of agent you can build. That’s the real architectural decision hiding behind the feature comparison tables.
Sources
- Anthropic launches Memory for Claude Managed Agents
- Stash: persistent memory for any MCP-compatible agent
- Scaling Test-Time Compute for Agentic Coding (Meta)
- Mem0 vs Zep (Graphiti): AI Agent Memory Compared
- AI Agent Memory Systems in 2026: A Comprehensive Comparison
- Honcho: Memory That Reasons
- Cloudflare can remember it for you wholesale
- How agentic AI strains modern memory hierarchies
- HN: Building AI agents with persistent memory